
こんにちは、ツシマです。
今回は、ANOVAについて解説していきます。
まだt検定の記事をご覧になっていない方は、そちらからお読みください。
3つ以上のグループを比べたい!!!
以前、「2つのグループの違い」を調べるt検定について学んできましたね。
全て2つの値だけ比べられたら良いですが、世の中はそこまで単純ではありません。
例えば、こんな場面に遭遇したらどうしましょう?
- 3つのダイエット法を比べたい!
- 4つの病院の治療成績を比べたい!!
- 5つの地域の感染症発症率を比べたい!!!
これだと、もうt検定だけに頼ることができません。
そこで登場するのが本日の主人公、ANOVA(分散分析)です!!
バトルロイヤルの審判、ANOVA
ANOVAは、「複数グループの平均値に差があるか」を調べるための方法です。
想像してみてください。
看護師の部署が10個あったとします。
「どの部署の看護師が詰め所のお菓子を一番多く食べる?」「どの部署の看護師が一番ナースコールに出るのが早い?」
部署ごとの平均値で優勝を決める大会をすることになりました。
しかし、t検定で一つ一つの部署を比較していたら日が暮れてしまいます。
そこで、優秀な審判のANOVAに登場してもらいます!!
ANOVAは「まとめてジャッジしましょう!!」と一斉に10部署のデータを比べてくれるのです。
t検定がタイマン勝負なら、ANOVAはバトルロイヤルです。
一気に全員を戦わせる(=平均を比べる)、大胆な検定です。
どうやって比べるの?──分散に注目!
では、ANOVAはどうやって公平にジャッジするのでしょうか?
カギは、「分散(バラつき)」にあります。
- グループ内のバラつき(同じグループ内でどれくらい違うか)
- グループ間のバラつき(複数のグループでどれくらい違うか)
この2つを並べて、
- グループ内のバラつきが大きい→「グループ内でバラバラなだけかも?」
- グループ間のバラつきが大きい→「平均値に差がありそう!」
と判断します。
つまり、「内部よりも、外部とのケンカの方が激しいか?」
それを冷静に見ているのが、ANOVAの仕事です。
どんな結果が出るの?──F値とp値
ANOVAでは、最終的に2つの数字を見ます。
- F値:分散比(ケンカっぷりの激しさ)
- p値:確率(そのケンカが激しいのは偶然か)
このうち、特に重要なのが他の検定でもお馴染み、p値です!
p値が有意水準(大抵0.05)より小さければ、
「どこかのグループは明らかに違うっぽいぞ!!」
と結論付けられます。
注意!ANOVAではできないこと!
- 「違いがある」ことはわかるが、「違うところ」が分からない
ただし、ANOVAだけでは「どこのグループ同士が違うか?」まではわかりません。
後から「多重比較」という追加調査をして、具体的にどの部署同士が違うかを調べる必要があります。
「みんなでケンカをしていることは分かったけど、誰と誰が取っ組み合いをしているかは別途確認が必要」ということです。
- 前提条件が厳しい
ANOVAを使うには、
各グループのデータが正規分布に従っている
各グループの分散が等しい(等分散性)
という前提条件があります。
公平なバトルロイヤルをするために、厳しいルールを設けているようなものです。
- 外れ値に弱い
極端な値(外れ値)があると、分散が大きくなり、F値やp値に大きな影響が出ます。
例えば、地球人最強を決めるバトルロイヤルのはずが、参加者にスーパーサイヤ人がいたら他の参加者はひとたまりもありません。(ドラゴンボールの世界では日常茶飯事ですが)
つまり、超人や極端に弱い参加者がいないようにしないと、バトルロイヤルは成り立たないのです。
- サンプルサイズが小さいと信頼性が下がる
特に分散の推定はサンプル数が少ないと不安定になりがちです。
小規模データだと正確な結論を出しにくいです。
そのため、バトルロイヤルの参加者(=データの数)が多い場合にANOVAを使いましょう。
- 多重比較問題に注意が必要
「ANOVAで有意差あり」とわかった後に多重比較を何回もやると、偶然「差がある」と判定される確率が高まります。
何回も同じ参加者でバトルロイヤルをしたら、偶然一番強くない人が優勝してしまうことがあるようなものです。
そのため、ボンフェローニ補正(偽陽性の発生確率をコントロールする)等をする必要があります。
実際にExcelでバトルロイヤルを主催してみよう(ANOVA)
あなたは、A社、B社、C社に健康教育(ストレス対策講座)を行いました。
教育開始1ヶ月後の従業員のストレスレベル(スコア:0〜100点)を測定しました。点数が低いほど、ストレスが低いことを示しています。
職場ごとにストレス改善効果に違いがあるかをANOVAで検定してみます。
| A社 | B社 | C社 |
| 55 | 62 | 70 |
| 52 | 65 | 68 |
| 57 | 60 | 75 |
| 50 | 63 | 72 |
| 53 | 67 | 77 |
| 58 | 61 | 69 |
今回もいつもと同じように、Excelを使用します。
まず、「データ」タブ→「データ分析」→「分散分析:一元配置」を選択してください。
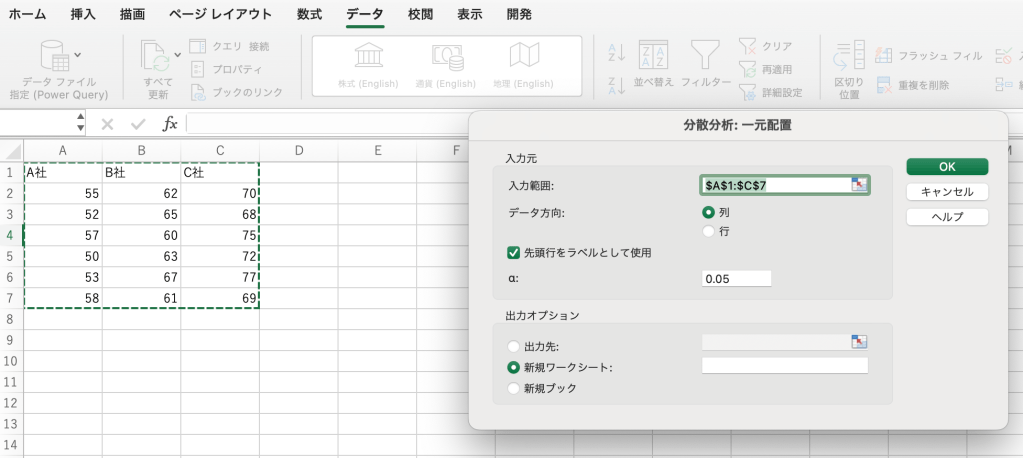
次に、データがある範囲を選択します。
今回はデータが列で並んでいるため、データ方向は「列」にします。
「先頭行をラベルとして使用」にもチェックを入れておくと、結果で「A社」、「B社」、「C社」と出るため見やすくなります。
結果を新しいワークシートに出したい場合は「新規ワークシート」、新しいブックに出したい場合は「新規ブック」を選んでください。
すると、結果が自動で出てきます。
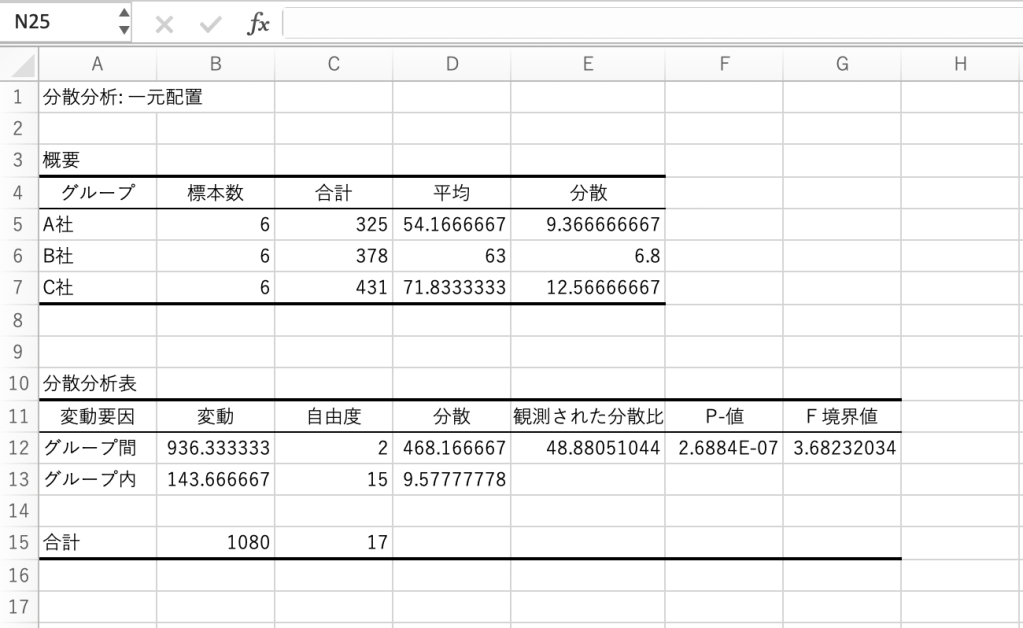
一つ一つ、データを解釈していきましょう。
細かい用語についてはt検定の記事ですでに触れているため、今回は簡単に説明します。
| 項目 | 結果 | 意味 |
| グループ間変動 | 936.33 | グループ同士(A社、B社、C社)の違いの大きさ |
| グループ内変動 | 143.67 | 各グループ内(同じ社内)の個人差の大きさ |
| 観測された分散比(F値) | 48.88 | 「グループ間の違い」と「グループ内の違い」の比率 |
| p値 | 2.6884E-07(=約0.00000026884) | 差が偶然で出た可能性(ほぼゼロ) |
| F境界値 | 3.68 | 「このくらいF値が大きければ、有意差ありと認めましょう!」という基準。 今回は明らかにF値>F境界値ですから有意差はあると考えられます。 |
t検定と同様、少しの操作だけでANOVAができます。
なお、ExcelでできるANOVAは3種類あります。まずは先ほど行った「一元配置ANOVA」からマスターすればOKです。
| 検定名 | 内容 |
| 分散分析:一元配置 | 最も基本的なANOVA たった一つの基準(分類)で、複数グループの平均値を比較する |
| 分散分析:二元配置(繰り返しなし) | 2つの要素(例:病院と治療法)を同時に考慮 |
| 分散分析:二元配置(繰り返しあり) | 同じ対象に繰り返し測定した場合に使う |
まとめ
- グループが3つ以上であれば、まずANOVAを使う。
- t検定を何度も繰り返すより、ANOVAでまとめて調べた方がスマート。
- もし差があることが分かったら、多重比較でさらに調べる。
ぜひあなたも、バトルロイヤルの名主催者を目指してください!
おまけ:PythonでANOVAを実施する
一元配置ANOVA
import pandas as pd
from scipy import stats
# データ読み込み
df = pd.read_excel('ファイルパス名')
# 各グループのデータを取り出す
a = df['A社']
b = df['B社']
c = df['C社']
# 一元配置ANOVA
f_statistic, p_value = stats.f_oneway(a, b, c)
# 結果表示
print(f"F値(F-statistic): {f_statistic:.4f}")
print(f"P値(p-value): {p_value:.8f}")
# 有意差判定(有意水準5%)
if p_value < 0.05:
print("有意差あり!どこかのグループで平均に差があります。")
else:
print("有意差なし。グループ間に大きな違いは見られません。")
出力:
F値(F-statistic): 48.8805
P値(p-value): 0.00000027
有意差あり!どこかのグループで平均に差があります。
Excelと同じ結果が出ますが、Pythonであっても事前にANOVAの前提条件にデータが当てはまっているか確かめる必要があります。
二元配置ANOVA
職場(A社/B社/C社) × 性別(男性/女性)でストレススコアを比較します。
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
# データ作成
df = pd.DataFrame({
'ストレススコア': [55, 52, 57, 50, 53, 58, 62, 65, 60, 63, 67, 61, 70, 68, 75, 72, 77, 69],
'職場': ['A社']*6 + ['B社']*6 + ['C社']*6,
'性別': ['男', '女', '男', '女', '男', '女']*3
})
#データ表示
print(df)
# モデル作成(職場と性別の両方を説明変数にする)
model = ols('ストレススコア ~ 職場 + 性別 + 職場:性別', data=df).fit()
# ANOVA実行
anova_table = sm.stats.anova_lm(model, typ=2)
# 結果表示
print(anova_table)
出力:
ストレススコア 職場 性別
0 55 A社 男
1 52 A社 女
2 57 A社 男
3 50 A社 女
4 53 A社 男
5 58 A社 女
6 62 B社 男
7 65 B社 女
8 60 B社 男
9 63 B社 女
10 67 B社 男
11 61 B社 女
12 70 C社 男
13 68 C社 女
14 75 C社 男
15 72 C社 女
16 77 C社 男
17 69 C社 女
sum_sq df F PR(>F)
職場 936.333333 2.0 50.461078 0.000001
性別 18.000000 1.0 1.940120 0.188923
職場:性別 14.333333 2.0 0.772455 0.483538
Residual 111.333333 12.0 NaN NaN
Residualとは、モデルでは説明できなかったズレや誤差のことです。つまりこれが大きいと、調査したもの以外にも原因が隠れている可能性があります。
今回、p値を調べて有意差があったのは「職場ごとの違い」でした。
繰り返し測定ANOVA
健康講座前後のストレススコアの変化を見ていきます。(同じ人に2回測定)
import pandas as pd
import pingouin as pg
# データ作成
df = pd.DataFrame({
'被験者': [1, 2, 3, 4, 5],
'前': [60, 58, 62, 65, 59],
'後': [55, 53, 57, 60, 54]
})
# データ表示
print(df)
# データをlong形式に変換
df_long = pd.melt(df, id_vars=['被験者'], value_vars=['前', '後'],
var_name='時期', value_name='ストレススコア')
# 繰り返し測定ANOVA実施
anova_result = pg.rm_anova(dv='ストレススコア', within='時期', subject='被験者', data=df_long, detailed=True)
# 結果表示
print(anova_result)
出力:
被験者 前 後
0 1 60 55
1 2 58 53
2 3 62 57
3 4 65 60
4 5 59 54
Source SS DF … p-unc ng2 eps
0 時期 6.250000e+01 1 … 4.846761e-33 0.503626 1.0
1 Error 7.105427e-15 4 … NaN NaN NaN
ちょっとわかりにくいので、詳しく見ていきます。
| 項目 | 値 |
| Source(要因) | 時期(例:介入前・介入後) |
| SS(Sum of Squares、平方和) | 62.5 |
| DF(自由度) | 1 |
| F(F値) | 非常に大きい(実際にはここは省略されることもある) |
| p-unc(p値) | 4.846761e-33(=とても小さい) |
| ng2(効果量、η²) | 0.5036 |
| eps(球面性補正) | 1 |
1. Source:要因(時期)
- ここで比較しているのは「時期」です(講座前VS 講座後)
- つまり、同じ人に対して時間差で2回測定した比較です。
2. SS(平方和)
- 62.5 → 「時期によるスコアの違いのバラつきの大きさ」です。
- 簡単に言えば、「前後でどれくらいストレススコアが動いたか」の量です。
3. DF(自由度)
- 1 → 比較しているのは「2時点(前後)」です。自由度=2−1=1
4. p-unc(p値)
- 4.846761e-33(=0.000…..)
- 有意水準0.05よりはるかに小さいので、
「時期によってストレススコアに有意な変化があった」と強く結論づけられます。
5. ng2(効果量:ナイーブ効果量)
- 効果量(η², イータ二乗)=0.5036
- 「介入または他の要因による変化がどれくらい大きかったか」を表す指標です。
参考基準:
| 効果量(η²) | 評価 |
|---|---|
| 0.01 | 小さい効果 |
| 0.06 | 中程度の効果 |
| 0.14以上 | 大きい効果 |
0.50はとても大きな効果です。
つまり、健康講座などがストレススコアにかなり強い影響を与えたと推測できます。
6. eps(球面性補正)
- 1.0
- 球面性(sphericity)とは、繰り返し測定のときに「誤差構造が均一か?」を見る性質です。
- ここではeps=1.0なので、球面性の仮定を完全に満たしているとわかります。
3時点以上比較(例:前・中間・後)になるとeps補正(イプシロン補正)が重要になりますが、今回のような2時点(前後比較)なら基本気にしなくてOKです。
せっかくなので、もう少し球面性について補足します。
同じ人に何度も(例:前・中・後)測定していると、「測定値同士が似ている」(相関してる)ことがあります。
そのとき、「誤差の大きさが各ペア(1人分のデータ)で同じか?」について考えることが重要になります。
例として、
- 「前 → 中間」スコアの差のバラつき
- 「中間 → 後」スコアの差のバラつき
- 「前 → 後」スコアの差のバラつき
→ これらの差のバラつき(分散)が全部同じなら、球面性がある(満たされている)と考えられます。
もう少し詳しくイメージすると、
- 球面性がある状態
3つの試験を行った時、どのペアでも点数のズレ方がだいたい同じ
→ 比較がフェア!
- 球面性がない状態
「前→中間」は安定してるけど、「中間→後」はバラつきが大きすぎ!」
→ 比較が偏っていて危ないかも!?
ということです。
そして、eps(イプシロン)とは、球面性がどれくらい満たされているかを示す指標です。
| epsの値 | 球面性の状態 | 補正の必要性 |
| 1.0 | 完璧に満たしている | 補正不要 |
| 0.75〜1.0 | だいたいOK | 補正しても誤差程度 |
| 0.5以下 | 危険!! | 補正が必要!!! |
では、eps補正とは何でしょうか?
球面性が満たされていないと、F値が「大きすぎ」に出てしまう(=本当は有意ではないのに有意に見える)ことがあります。
そんな時に、eps補正は、
- F値の計算に使う自由度を小さくする
- p値を厳しめに調整する
ということをします。
主なeps補正の種類もご紹介します。
| 補正法 | 特徴 |
| グリーンハウス・ガイサー(Greenhouse-Geisser) | 厳しめ、安全寄りの補正。 epsが小さく出る傾向がある。 |
| ホイン・フェルト (Huynh-Feldt) | やや緩め、自由度が高めになる。 |
ここまで聞き慣れない用語がたくさん現れましたが、一つずつ落ち着いて理解していきましょう!!
