
今回は「モデルの性能と汎化性能ってどうやって数式で考えるの?」というお話です。
モデルの性能と汎化性能については前回の記事に詳しく載っているため、こちらが未読の方は先にお読みください。
お馴染みの「中学生でも分かる!?」シリーズで、今回もやさしく学びましょう!
それでは、レッツゴーーーー!!!
誤差を分解してみよう
モデルの誤差を示す式は、下記の通りです。

登場人物:
:バイアス2(思い込みの強さ)
:バリアンス
:不可避誤差(ノイズ)
このバイアス、バリアンス、不可避誤差のバランスが「モデルの汎化性能」を決めます。
バイアスを下げようと頑張りすぎると、バリアンスが上がってしまう。
これが バイアス・バリアンスのトレードオフ です。
数式で見える「過学習」
「学習しすぎて失敗」=過学習です。
これは数式でいうと、バリアンスが大きすぎる状態です。
- 学習データ:完璧に当てはまる
- 新しいデータ:全然当たらない

登場人物:
:損失関数
:実際の値(真の答え)
:モデルの予測値
:誤差の二乗(ズレの大きさ)
:全データの誤差を合計
この数値が大きいと、学習しすぎて新しいデータに対応できていない可能性が高いです。
バイアス²+バリアンスのバランスを見る

モデルの複雑さを上げていくと:
- バイアス² : 減る
- バリアンス : 増える
その合計(総誤差)が一番小さくなる地点が、
最適な複雑さ=汎化性能が最高の点です。
前回の記事の図をもう一度見てみましょう。
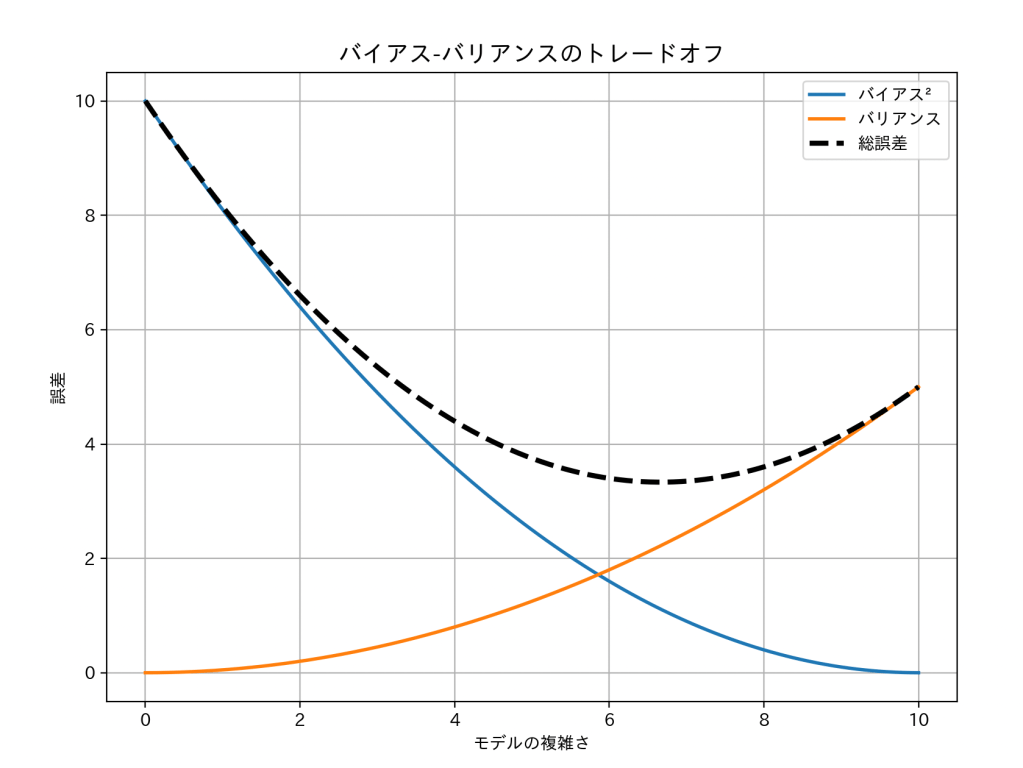
この図だと、複雑さ6あたりがまさにそれですね。
正則化とペナルティ(罰則)
ここで登場するのが 正則化(regularization)です。
これは「やりすぎモデルにペナルティ(罰)を与える」という仕組みです。

登場人物:
:通常の誤差(二乗誤差)
- λ :罰則の強さ(大きいほど制約が強い)
:正則化項(L1、L2など)
L1正則化(ラッソ回帰)

登場人物:
:通常の二乗誤差
:罰則の強さ
:L1ペナルティ
:係数(重み)
つまり、係数(重み)の絶対値の和をペナルティにしています。
L2正則化(リッジ回帰)

登場人物:
:L2ペナルティ(なめらかに縮める)
これで、モデルをなめらかにするのです。
L1+L2の折衷(エラスティックネット)

登場人物:
- λ1:L1ペナルティの強さ
- λ2:L2ペナルティの強さ
このように、2つのペナルティを組み合わせて、より良いモデルにするため調整します。
まとめ
簡単にまとめると、
- バイアス2:思い込みの強さ
- バリアンス:ブレの大きさ
- ペナルティ:モデルのやりすぎ防止
- λ:ペナルティの強さ
数学はモデルを縛るためではなく、自由にさせすぎて失敗させないための優しさです。
何もかもバランスが大事ですね。
ではでは、次の記事でお会いしましょう!!!
