
お待たせしました、毎回恒例の中学生でも分かる!?機械学習の数学シリーズです。
今回のテーマはSVM、勾配ブースティングの数式です。
そもそもSVM、勾配ブースティングって何?という方は過去記事をご参照ください。
今回も数式をやさしく分解して説明するので、ついて来てくださいね〜〜〜
それでは、レッツゴーーーー!!!!!!
SVMの数式
基本形

登場人物:
:線の向きを決めるベクトル
:データ
:線の位置をずらす定数
この1本の線(または面)で、チームを分けるのが目的です。
ここで出てくる「・」とは、ベクトルの内積、いわゆる「
マージン最大化
SVMが特別なのは、できるだけ広い余白(マージン)をとることでした。
これを式で書くとこうなります。


線の傾きを表す
「境界線がゆったり構えている」イメージです。
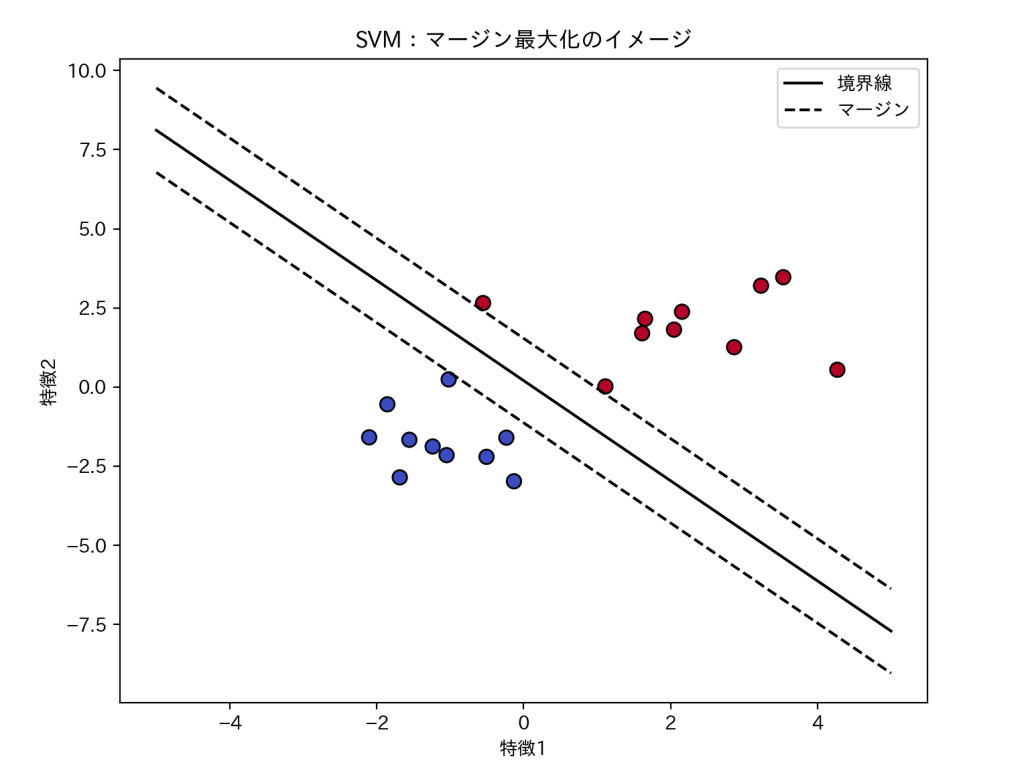
図にするとイメージしやすいですね。
間違えたくない!でも現実のデータでは上手くいかん…
現実のデータでは、厳密にデータを分けようとすると、うまくきれいに分けられないこともあります。
そのため、少しの誤差を許す「ソフトマージンSVM」という形にします。

登場人物:
:厳しさを決めるパラメータ(大きいと厳しく、小さいと寛容)
:各データがどれだけ間違えているか(スラック変数)
:各データの間違いを足していく
つまり、「できるだけ厳密に分けたいけど、多少の例外はOK」という現実的な折衷案です。
カーネル法
線では分けられない時は、空間でデータをとらえます。

登場人物:
:データの見方を変える関数
:カーネル関数(距離の測り方)
代表例としては、
- 線形カーネル(Linear Kernel):シンプルで速い
- RBFカーネル(Gaussian Kernel):曲線で分けられる
があります。
勾配ブースティングの数式
予測を少しずつ改善する
ブースティングの考え方は「前回のミスを次で修正」です。

登場人物:
:m回目(今回)の予測モデル
:m-1回目(前回)の予測モデル
:新しく学んだ弱学習器
:学習率(どのくらい修正するか)
つまり、「前回の予測+今回のちょっとした修正」を何度も積み重ねて、少しずつ賢くなっていくのです。
イメージ図をご覧ください。
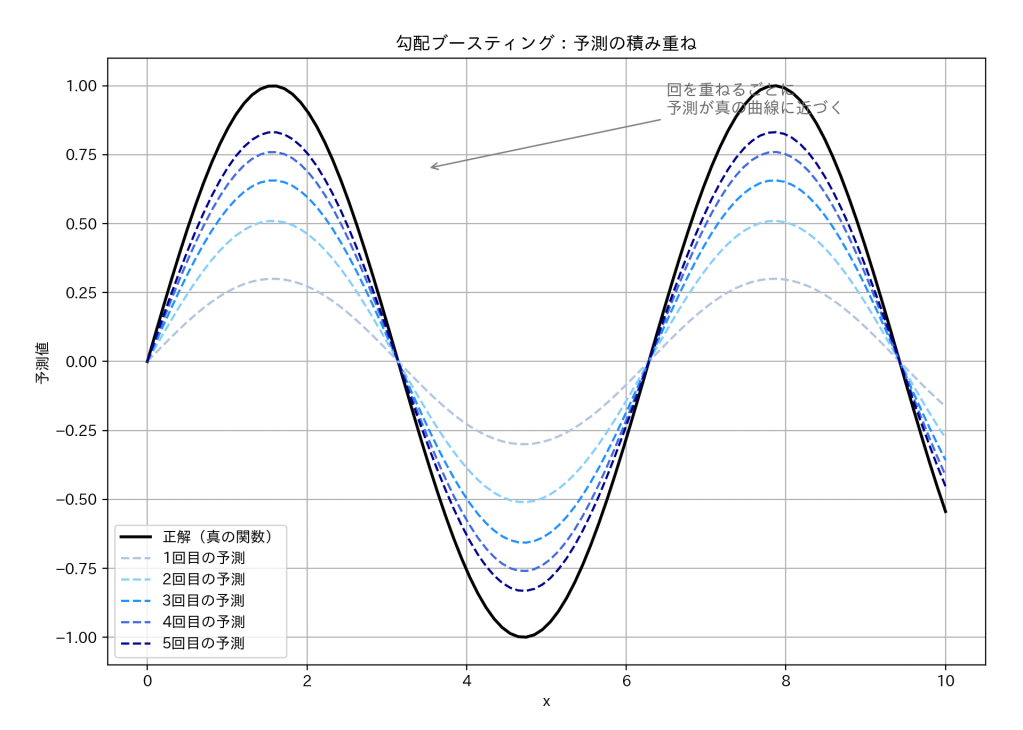
このように何度も予測を繰り返すことで、予測が正解に近づいていきます。
勾配って何?
「勾配」はどの方向に間違っているかを教えてくれるベクトルです。
数学的には誤差関数の傾きです。

登場人物:
:損失関数(どれくらい間違えているか)
:偏微分(他の要因はそのままにして、1つの変数だけ動かしたときの変化量)
:そのデータに対して「どっちに直せばいいか」の方向
マイナス(−)がついているのは、「間違いを減らす方向に進む」、という意味です。
ブースティングではこの
「次はどこを直せばいいか」を決めていきます。
損失関数についてのグラフを見てみましょう。
分かりやすくするために、ここでは代表的な損失関数である「平方誤差損失関数」を例に説明します。
これは、予測値 

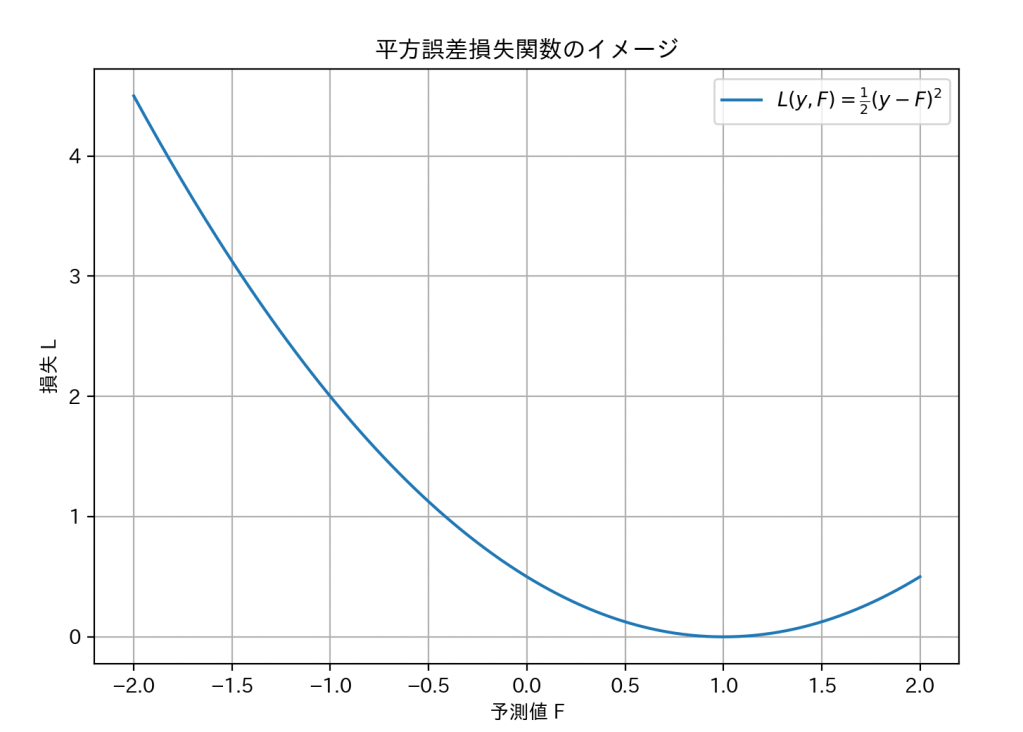
グラフの一番低い部分(このグラフでは1.0付近)が「損失(誤差)が最も小さい=予測が一番正確な状態」です。
機械学習は、この谷底を目指してパラメータを少しずつ調整していくのです。
最後の予測
すべての弱学習器を足し合わせて最終予測を作ります。

登場人物:
:全体のステップ数(弱学習器の数)
:それぞれの小さな修正(微調整)
おわりに
今回の数学記事で理解を深められたでしょうか?
数学は見た目は難しいですが、少しだけでも親しみを持ってもらえると嬉しいです。
それでは、次の記事でお会いしましょう!!!
