
今回は、ディープラーニング(深層学習)が考える流れと反省の仕組みをまとめてのぞいてみます。
ディープラーニングは、ただ「予測するだけ」じゃなく、
「どこを間違えたか」をきちんと自分で反省して、少しずつ成長していきます。
難しそう?大丈夫です!
いつもと同じように、数式を分解して、やさしく説明していきます。
それでは、レッツゴーーーー!!!
順伝播(forward propagation)
AIが情報を受け取って、出力を出す流れを「順伝播」といいます。

登場人物:
:入力データ
:重み(どの情報をどれくらい重視するか)
:バイアス
:計算結果
活性化関数(activation function)
AIが「入力をどう解釈するか」を決めるスイッチが活性化関数です。
その中でも代表的なものを紹介します。
ReLU(レル)関数

0以下の値は切り捨て、0以上だけを通す関数です。
AIに「関係ない情報はスルーして!」と言っているようなものです。
Tanh(ハイパボリックタンジェント)関数

出力が −1〜1 の間に収まる関数です。
プラス方向にもマイナス方向にも反応できるバランス型です。
シグモイド関数
「ん?どこかで見たことあるぞ、この名前…」という方、鋭い!!
ちなみに、ロジスティック回帰で出てきたあの シグモイド関数
どんなのだったか忘れたよ…という方は、過去記事もご覧ください。
出力が 0〜1 の間に収まる関数です。
小さい値は0に近づき、大きい値は1に近づくため、確率のような結果を出したいとき(Yes/No判定など)に便利です。
損失関数(Loss Function)
AIが「どのくらい間違えたか」を数値化するのが損失関数(Loss Function)です。
テストでいうと「減点方式」です。
ディープラーニングでは、回帰タスクでは平均二乗誤差(MSE)が定番です。

登場人物:
:正解
:予測値
:損失(間違いの大きさ)
AIはこの
誤差逆伝播法(backpropagation)
AIが「自分のどこを直せばいいか」を考える方法です。
名前の通り、誤差を逆向きに伝えて重みを修正します。
基本式

(※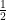
ここから、「どの重みをどう直すか」を探します。
つまり、
連鎖式に原因をたどる
たとえば、

登場人物:
:予測を変えると損失がどう変わる?
:活性化関数の影響
:入力の影響
この連鎖の掛け算が、逆伝播の心臓部なのです。
勾配降下法
どこを間違えたか分かったら、あとは修正するのみです!
AIは誤差が大きい方向の逆へ、少しずつ進んでいきます。

登場人物:
:現在の重み(現在の考え方の癖)
:学習率(learning rate)
つまり、誤差が増える方向の逆に進んでいるのです。
まとめ
結局AIは、
- 順伝播:「考える」
- 損失関数: 「間違いを測る」
- 逆伝播 :「原因を探す」
- 勾配降下法 :「ちょっとずつ直す」
という過程をたどっているのです。まるで人間みたいですね。
私達もAIも、間違えながら成長しているのです。
だから、これからも焦らず、一緒に学んでいきましょう。
